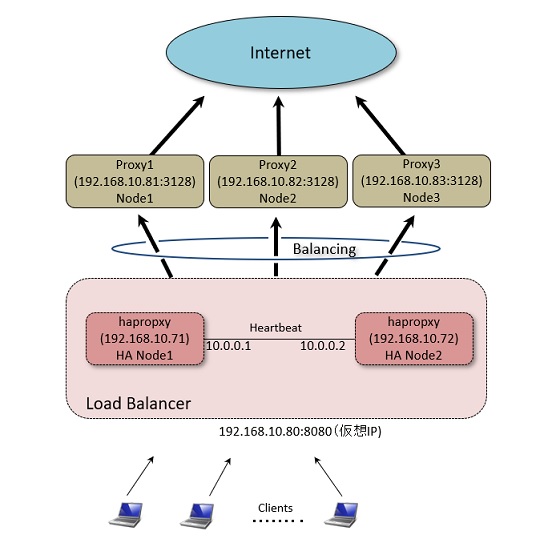
1-1. HAProxyのインストール
(1).Debian6の場合
以下の手順でHAProxyをインストールします。
| 実行コマンド |
実施対象 |
|
$ sudo apt-get update
$ sudo apt-get install haproxy
|
HA Node1
HA Node2 |
インストール後、デフォルトの起動設定ファイルを編集し、サービスが起動するようにします。
■ /etc/default/haproxy の修正
# Set ENABLED to 1 if you want the init script to start haproxy.
# ENABLED=0
ENABLED=1
# Add extra flags here.
#EXTRAOPTS="-de -m 16"
(2). Debian7の場合
Debian7を使う場合には、backportsにパッケージがあるので、以下のようにすることでbackportsのパッケージを使うこともできます。
なお、Debian7 の初期パッケージでは以下で説明する Pacemaker が機能しないためOSを含め最新のものを使うようにしてください。
(2014/11/9現在の Linux 3.2.0-4-amd64 、 HAProxy 1.5.6-1 では動作するようです)
$ sudo echo "deb http://ftp.debian.org/debian/ wheezy-backports main"
>> /etc/apt/sources.list
$ sudo apt-get update
$ sudo apt-get install haproxy
1-2. HAProxyの設定
/etc/haproxy/haproxy.cfg の設定 (HA Node1, HA Node2ともに共通)
# this config needs haproxy-1.1.28 or haproxy-1.2.1
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
#log loghost local0 info
maxconn 4096 # --- 最大接続数
#chroot /usr/share/haproxy
user haproxy
group haproxy
daemon
#debug
#quiet
pidfile /var/run/haproxy.pid # --- Heartbeatで必要となるので指定しておくこと
defaults # --- デフォルト値の定義
log global
mode http # --- L7(HTTP)モードで動作させる
option httplog
option dontlognull
retries 3
option redispatch # --- cookie使用中に利用中のProxyサーバが不調の場合、別のProxyに切り替えて接続を継続する
maxconn 4096 # --- デフォルトの最大接続数
contimeout 5000
clitimeout 50000
srvtimeout 50000
# listen webfarm 0.0.0.0:8080
listen webfarm
192.168.1.20:8080
mode http
cookie SERVERID insert indirect nocache
balance roundrobin # --- ラウンドロビン方式で負荷分散を行う。セッションの維持を考えると "balance
leastconn" の方が良いと思われる。
option httpclose
option forwardfor # --- 上位のProxyへクライアントIPを渡す
server proxy1 192.168.1.10:3128 check inter 2000 rise 2 fall 5 # --- 上位のProxyサーバの指定。2秒間隔でヘルスチェックし、5回反応しないと落ちていると判断。2回成功すれば復旧。
server proxy2 192.168.1.11:3128 check inter 2000 rise 2 fall 5
server proxy3 192.168.1.12:3128 check inter 2000 rise 2 fall 5
以上で、HAProxyの設定は完了です。続いて、ロードバランシングが正しく機能しているか試していきます。
1-3. HAProxyの動作確認
上記の設定を行うことで、"HA Node1"、"HA Node2"ともにロードバランサとして機能するようになっています。ただし、それぞれのHA
Propxyの設定においてロードバランサの待ち受けアドレスを"192.168.1.20:8080" としている為に、同時に起動する事はできません。 そこで以下のように1台づつ確認していきます。
(1). 仮想IPを割り当て HA Proxy を起動します。
$ sudo ifconfig eth0:1 192.168.1.20 netmask 255.255.255.0 up
$ sudo /etc/init.d/haproxy restart
(2). クライアントを使ってWebサイトにアクセスしログを確認ます。
ブラウザの設定で、Proxyとして "192.168.1.20:8080" を指定して、適当なインターネット上のWebサイトにアクセスしてみます。 この結果、Proxy1
~ Proxy3 の各Proxyのアクセスログに、そのサイトへのアクセスした記録が残ります。
ログファイルは、"/var/log/squid/access.log" です。
(3). HAProxyの停止、仮想IPを解放します。
$ sudo /etc/init.d/haproxy stop
$ sudo ifconfig eth0:1 down
2. Heartbeat / Pacemaker による冗長化
上記までの作業で、"HA Node1"、"HA Node2"の2つのロードバランサの用意ができました。 しかし、このままでは2つのロードバランサの切り替えを手動で行う必要があり、可用性が確保できません。 そこで、システムの冗長化を実現するための Heartbeat というソフトを導入して、2つのロードバランサを稼働系/待機系として構成し通常は稼働系でバランシング処理を行い、稼働系に障害があった場合に待機系に自動で切り替わるようにしていきます。(ここでは"待機系","稼働系"という言葉を使っていますが、以下の設定では主にどちら一方が稼働系に成る訳ではありません。 先に起動したサーバから稼働系となります)
なお従来、Heartbeat は1つのソリューションとして提供されていましたが、現在の Ver.3 からは Heartbeat でハードの監視系を行いソフトの監視は
"Pacemaker" というモジュールで行うようになっています。(詳しくはこちら)
パッケージとしては "heartbeat" をインストールすることで "pacemaker" も一緒にインストールされます。
2-1. インターコネクト(ハートビート用)LANの準備
Heartbeat を利用する場合、相手のサーバの死活監視を行うためのインターコネクトを用意する必要があります。 これはシリアルまたはLANケーブルを利用するもので、通常はLANを利用するのが簡単だと思われます。 必要に応じて、それぞれのHA
NodeサーバにLANインターフェースを増設します。 増設したインターフェースが認識できていれば
| 実行コマンド |
実施対象 |
|
$ sudo ifconfig -a
|
HA Node1
HA Node2 |
を実施することで、インターフェースが確認できる筈です。 ここでは、 "eth1" として増設LANボードが認識できているものとして話を進めます。
eth1 のインターフェースに以下のようしてIPアドレスを設定します。
■ /etc/network/interfaces の設定 (HA Node1)
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
#- allow-hotplug eth0
#- iface eth0 inet dhcp
# -
allow-hotplug eth0
auto eth0
iface eth0 inet static
address 192.168.1.21
netmask 255.255.255.0
gateway 192.168.1.254
auto eth1
iface eth1 inet static
address 10.0.0.1
netmask 255.255.255.0
■ /etc/network/interfaces の設定 (HA Node2)
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
#- allow-hotplug eth0
#- iface eth0 inet dhcp
# -
allow-hotplug eth0
auto eth0
iface eth0 inet static
address 192.168.1.22
netmask 255.255.255.0
gateway 192.168.1.254
auto eth1
iface eth1 inet static
address 10.0.0.2
netmask 255.255.255.0
注意として、インターコネクト同士を接続する場合、マシン間にHUBを置かずに直結するようにして下さい。そうしないと、HUBが単一障害点となり冗長化による信頼性が低下します。どうしてもHUBを経由する必要がある場合にはインターコネクト用LANを各マシンで2経路分用意して、それぞれ別のHUBを経由するような工夫をしてください。
2-2. Heartbeatのインストール
以下の手順で Heartbeat をインストールします。
| 実行コマンド |
実施対象 |
|
$ sudo apt-get install heartbeat
|
HA Node1
HA Node2 |
2-3. ノード名の確認
Heartbeat では HA ノード間の接続にマシン名を使用します。 そのため、マシン名(HAノード名)を使ったネットワーク接続が正常に行えるようにしておく必要があります。
現在のマシン名を確認する場合、以下のコマンドを実施します。
| 実行コマンド |
実施対象 |
|
$ uname -n
hanode1
|
HA Node1
HA Node2 |
ここに表示される名前は、/etc/hostname ファイルに定義されています。 この名前を使ってネットワークを接続するには、DNSをきちんと定義するか、/etc/hosts
ファイルに名前を登録して必要があります。 ここでは、説明を簡略化するため、/etc/hosts を次のように設定したものとします。
■ /etc/hosts の設定 (HA Node1, HA Node2ともに共通)
ここでの名前は、必ず"uname -n"の結果と合わせてください。 そうしない場合はHeartbeatの起動に失敗します。
127.0.0.1 localhost
192.168.1.21 hanode1.example.jp hanode1
192.168.1.22 hanode2.example.jp hanode2
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
2-4. HAProxyサービスが自動起動しないようにする
Heartbeat を使った場合、HA構成内で動かすサービスは Heartbeat によって起動させる必要があります。 そのため、サービス通常の
Init 処理で自動的に起動されないように設定しておく必要があります。今回は、"haproxy"サービスは Heartbeat
にて起動されるので、"haproxy"サービスが自動起動しないようにします。
$ sudo /etc/init.d/haproxy stop # --- 上記作業( 1-3-(3) )で止めていいない場合
$ sudo update-rc.d haproxy disable
2-5. Heartbeat 用設定ファイルの入手
インストール直後は、何も設定ファイルができていないので以下の手順で設定ファイルを所定の場所にコピーします。
$ cd /etc/ha.d
$ sudo cp /usr/share/doc/heartbeat/authkeys authkeys
$ sudo chmod 0600 authkeys
$ sudo zcat /usr/share/doc/heartbeat/ha.cf.gz > ha.cf
$ sudo zcat /usr/share/doc/heartbeat/haresources.gz > haresources
2-6. 設定ファイルの編集(Heartbeat)
2-6-1. 認証コードファイルの編集
■ /etc/ha.d/authkeys の設定 (HA Node1, HA Node2ともに共通)
auth 2 # --- 暗号方式として sha1 を使う (CRC, MD5は単に定義しているだけ)
1 crc
2 sha1 haproxy_Password # --- パスワードとして"haproxy_Password"を指定
3 md5 Hello!
2-6-2. 設定ファイルの編集
■ /etc/ha.d/ha.cf の設定 (HA Node1)
::
::
# Facility to use for syslog()/logger
#
logfacility local0
::
# keepalive: how long between heartbeats?
#
keepalive 2
::
# deadtime: how long-to-declare-host-dead?
#
# If you set this too low you will get the problematic
# split-brain (or cluster partition) problem.
# See the FAQ for how to use warntime to tune deadtime.
deadtime 30
::
# warntime: how long before issuing "late heartbeat" warning?
# See the FAQ for how to use warntime to tune deadtime.
warntime 10
::
# What UDP port to use for bcast/ucast communication?
#
udpport 694
::
# Set up a unicast / udp heartbeat medium
# ucast [dev] [peer-ip-addr]
#
# [dev] device to send/rcv heartbeats on
# [peer-ip-addr] IP address of peer to send packets to
#
ucast eth1 10.0.0.2 # --- Heartbeat で監視する相手のIPアドレス
::
# The default value for auto_failback is "legacy", which
# will issue a warning at startup. So, make sure you put
# an auto_failback directive in your ha.cf file.
# (note: auto_failback can be any boolean or "legacy")
#
auto_failback off # --- 待機系へ切り替わった場合、稼働系が動き出した際に切り返す場合は "on" (時間を節約するなら"off")
::
# Tell what machines are in the cluster
# node nodename ... -- must match uname -n
#node ken3
#node kathy
#
# HA の対象となるノードの名前を指定。
node hanode1 # --- それぞれのノードの "uname -n"での名前と一致する名前を指定すること。
node hanode2
■ /etc/ha.d/ha.cf の設定 (HA Node2)
::
::
# Facility to use for syslog()/logger
#
logfacility local0
::
# keepalive: how long between heartbeats?
#
keepalive 2
::
# deadtime: how long-to-declare-host-dead?
#
# If you set this too low you will get the problematic
# split-brain (or cluster partition) problem.
# See the FAQ for how to use warntime to tune deadtime.
deadtime 30
::
# warntime: how long before issuing "late heartbeat" warning?
# See the FAQ for how to use warntime to tune deadtime.
warntime 10
::
# What UDP port to use for bcast/ucast communication?
#
udpport 694
::
# Set up a unicast / udp heartbeat medium
# ucast [dev] [peer-ip-addr]
#
# [dev] device to send/rcv heartbeats on
# [peer-ip-addr] IP address of peer to send packets to
#
ucast eth1 10.0.0.1
::
# The default value for auto_failback is "legacy", which
# will issue a warning at startup. So, make sure you put
# an auto_failback directive in your ha.cf file.
# (note: auto_failback can be any boolean or "legacy")
#
auto_failback off # --- 待機系へ切り替わった場合、稼働系が動き出した際に切り返す場合は "on" (時間を節約するなら"off")
::
# Tell what machines are in the cluster
# node nodename ... -- must match uname -n
#node ken3
#node kathy
node hanode1
node hanode2
注).iptablesを有効にしている場合、ucastで指定するハートビート用インターフェース間の通信ができるようにルールを設定するのを忘れないこと。
2-6-3. リスースファイルの編集
Heartbeat プロセスが起動した際に、稼働系で起動するリソースを定義ファイルに定義します。 今回は、仮想IPを割り当てた後に haproxy
プロセスを起動するように定義を行います。
■ /etc/ha.d/haresources の設定 (HA Node1)
hanode1 192.168.1.20/24/eth0 haproxy # hanode1では、仮想IPをeth0に割り当ててから haproxy サービスを起動
■ /etc/ha.d/haresources の設定 (HA Node2)
hanode2 192.168.1.20/24/eth0 haproxy
以上で Heartbeat の設定は完了です。設定にミスがなければ、"HA Node1", "HA Node2"をそれぞれ再起動することで、先に起動できたマシンでHAProxyが動作している筈です。
(起動するまで、少し時間がかかります)
また "sudo ifconfig -a" を実行することで、仮想IPが設定できているかを確認しても良いでしょう。 ここまでの作業で、一応HA構成ができているので稼働系をシャットダウンをするなどで停止すると、待機系でHAProxyが動き出すのを確認できると思います。
残念ながら、この状態でのHA構成は不完全な状態です。 なぜなら Heartbeat だけの HA 構成はサーバのハードウェア障害による待機系への切り替えには成功しますが、HAProxy
ソフトに障害が発生して止まってしまってもそれを検知できないため、待機系への切り替えに失敗します。
これに対処するために、引き続き Pacemaker の設定を行う必要があります。
現在のネットワークの状態の確認は以下のコマンドで確認できます。
$ sudo ip -f inet addr
2-7. 設定ファイルの編集(Pacemaker)
Pacemaker では、HA構成となっているプロセスなどを監視するとともに、稼働系で稼働させるリソースの定義を行います。 Debian のデフォルトの
Heartbeat では Pacemaker が動作しない状態になっているので、動作するように設定を行います。 設定は簡単で、 ha.cf ファイルに「crm
yes」のステートメントを追加するだけです。
/etc/ha.d/ha.cf の設定 (HA Node1, HA Node2 ともに)
::
::
crm yes
この設定後、それぞれのHA Nodeサーバを再起動してみてください。 すると先ほどまで動いていた HAProxy が動かなくなり、また仮想IPも割り当てされなくなる事と思います。
これはリソースの管理が Pacemaker に切り替わったためで正常な動作です。
2-7-1. Pacemakerの状態確認
現在のPacemakerの状態を確認します。
$ sudo crm_mon -1
hanode1 と hanode2 が正常に機能していれば、次のようにそれぞれのノードが「Online」となっている筈です。
============
Last updated: Sat Sep 28 19:16:29 2013
Stack: Heartbeat
Current DC: hanode1 (853969df-6ce5-4213-94f8-4ca9390d6900) - partition with quor
um
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, unknown expected votes
0 Resources configured.
============
Online: [ hanode1 hanode2 ]
2-7-2. リソースの定義
Pacemakerで監視・起動を行うリソースについて定義していきます。 なお、定義はどちらか一台のHA Nodeで実施します。 実施に当たっては両方の HA Node が Online になっていることを確認してから行ってください。
(1) 基本設定
クラスタ全体の動作に関わる基本的な設定を行います。
STONITH機能が働いていると、この機能をサポートするためのハードが無い状態での以後の設定に不都合なのでこれを無効にします。
また、リソースの状態に問題があった場合の再起動について、リソースの障害が4回発生するとフェイルオーバーし別のサーバに切り替わるように設定を変更します。
$ sudo crm configure property no-quorum-policy="ignore" stonith-enabled="false"
$ sudo crm configure rsc_defaults resource-stickiness="INFINITY"
migration-threshold="4"
(2) 仮想IPに関するリソースを定義
HAProxyサービスを提供する仮想IPを定義します。
$ sudo crm configure primitive vip_20 ocf:heartbeat:IPaddr2 \
params ip="192.168.1.20" nic="eth0" cidr_netmask="24"
op monitor interval="5s"
この時、以下のグループを実施する前に仮想IPとサービスが別々のノードで動いてしまうことがありますが、グループを設定後に再起動することで正常になる筈です。
設定した仮想IPの確認は、
$ sudo ip -f inet addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
inet 127.0.0.1/8 scope host lo
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 192.168.1.22/24 brd 192.168.1.255 scope global eth0
inet 192.168.1.20/24 brd 192.168.1.255 scope global secondary eth0
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 10.0.0.2/24 brd 10.0.0.255 scope global eth1
(3) HAProxy のリソースを定義
HAProxyサービスを定義します。
$ sudo crm configure primitive haproxyd lsb:haproxy op monitor interval="10s"
この設定では、監視・起動用のスクリプトとして "lsb:" すなわち/etc/init.d 以下にある "haproxy"
スクリプトを使っています。 "lsb:"スクリプトを使う場合には、その実行時のリターン値として決まった値を Pacemaker
が期待しています。 しかし、 Debian では HAProxy 稼働中に再度の起動(Start)を実施した場合の値が求める結果と違うので、これを修正します。
(4) グループの定義
仮想IPとサービスは常に同じサーバで動作させるために group の設定を行います。
$ sudo crm configure group HAproxy vip_20 haproxyd
(5) ネットワーク監視
サービスを提供するためのLANがネットワーク的に正常であることを確認します。デフォルトゲートウェイ(192.168.1.254)に Ping
を実施してLANが正常かを確認するようにします。また、ネットワーク監視はすべてのHA Nodeで行うようにするために、clone設定も実施します。
$ sudo crm configure primitive ckping ocf:pacemaker:pingd params name="default_ping_set"
\
host_list="192.168.1.254" multiplier="100" dampen="1"
\
op monitor interval="10s"
$ sudo crm configure clone clone_ping ckping
以上で Pacemaker の設定は完了です。 それぞれの HA Node を再起動して、どちらか一方で HAProxy が正常に動作することを確認してください。
また、Webブラウザの Proxy の設定で "192.168.1.20:8080" を指定して、正常にサイトが表示されることを確認してください。
3. 追加情報
3-1. リソースの確認
Pacemaker で設定したリソースを表示する場合には次のように行います。
$ sudo crm configure show
また、リソースのエラー情報を消す場合には以下のコマンドを実行します。 エラー情報が残っている状態では、その回数がスレッシュホールドの数を超えていると別サーバに切り替わってしまいます。
$ sudo crm resource cleanup haproxyd
3-2. リソースの削除
一部のリソースを削除したいのであれば、
(1) リソースの確認
$ sudo crm_resource --list
Resource Group: HAproxy
vip_20 (ocf::heartbeat:IPaddr2) Started
haproxyd (lsb::heartbeat:haproxy) Started
::
$
(2). リソースの停止と削除
$ sudo crm resource stop haproxyd
$ sudo crm configure delete haproxyd
を実行します。
Pacemaker で設定したリソースをすべて消去したい場合には次のように行います。
(1) HA Nodeの停止
$ sudo crm node standby hanode1
$ sudo crm node standby hanode2
(2) 設定の消去
$ sudo crm configure erase
(3) HA Nodeのオンライン化
$ sudo crm node online hanode1
$ sudo crm node online hanode2
3-3. OCFリソースエージェントの作成
上記の説明で、haproxy のリソース管理(開始、停止、ステータス等)には Linux 標準の init スクリプト(LSB) を使った設定を行っています。
しかし、init スクリプトは必ずしも Pacemaker に最適化された内容ではないために、場合によってはステータスの取り込みに失敗したり、開始や停止に失敗するケースも想定されます。
Pacemaker用のリソース管理には、OCFリソースエージェントを作成して管理する方が望ましいとなっています。 例えば haproxy 用の ocf ファイルは次のように準備します。(Debian7 では以下のOCFリソースエージェントでは正常に動作しないようすのでLSBで実行してください
$ sudo wget -O /usr/lib/ocf/resource.d/heartbeat/haproxy http://github.com/russki/cluster-agents/raw/master/haproxy
$ sudo chmod +x /usr/lib/ocf/resource.d/heartbeat/haproxy
■ /usr/lib/ocf/resource.d/pacemaker/haproxy
/usr/lib/ocf/resource.d/heartbeat/haproxy
#!/bin/sh
#
# Resource script for haproxy daemon
#
# Description: Manages haproxy daemon as an OCF resource in
# an High Availability setup.
#
# HAProxy OCF script's Author: Russki
# Rsync OCF script's Author: Dhairesh Oza <odhairesh@novell.com>
# License: GNU General Public License (GPL)
#
#
# usage: $0 {start|stop|status|monitor|validate-all|meta-data}
#
# The "start" arg starts haproxy.
#
# The "stop" arg stops it.
#
# OCF parameters:
# OCF_RESKEY_binpath
# OCF_RESKEY_conffile
# OCF_RESKEY_extraconf
#
# Note:This RA requires that the haproxy config files has a "pidfile"
# entry so that it is able to act on the correct process
##########################################################################
# Initialization:
: ${OCF_FUNCTIONS_DIR=${OCF_ROOT}/resource.d/heartbeat}
. ${OCF_FUNCTIONS_DIR}/.ocf-shellfuncs
USAGE="Usage: $0 {start|stop|status|monitor|validate-all|meta-data}";
##########################################################################
usage()
{
echo $USAGE >&2
}
meta_data()
{
cat <<END
<?xml version="1.0"?>
<!DOCTYPE resource-agent SYSTEM "ra-api-1.dtd">
<resource-agent name="haproxy">
<version>1.0</version>
<longdesc lang="en">
This script manages haproxy daemon
</longdesc>
<shortdesc lang="en">Manages an haproxy daemon</shortdesc>
<parameters>
<parameter name="binpath">
<longdesc lang="en">
The haproxy binary path.
For example, "/usr/sbin/haproxy"
</longdesc>
<shortdesc lang="en">Full path to the haproxy binary</shortdesc>
<content type="string" default="/usr/sbin/haproxy"/>
</parameter>
<parameter name="conffile">
<longdesc lang="en">
The haproxy daemon configuration file name with full path.
For example, "/etc/haproxy/haproxy.cfg"
</longdesc>
<shortdesc lang="en">Configuration file name with full path</shortdesc>
<content type="string" default="/etc/haproxy/haproxy.cfg" />
</parameter>
<parameter name="extraconf">
<longdesc lang="en">
Extra command line arguments to pass to haproxy.
For example, "-f /etc/haproxy/shared.cfg"
</longdesc>
<shortdesc lang="en">Extra command line arguments for haproxy</shortdesc>
<content type="string" default="" />
</parameter>
</parameters>
<actions>
<action name="start" timeout="20s"/>
<action name="stop" timeout="20s"/>
<action name="monitor" depth="0" timeout="20s" interval="60s" />
<action name="validate-all" timeout="20s"/>
<action name="meta-data" timeout="5s"/>
</actions>
</resource-agent>
END
exit $OCF_SUCCESS
}
get_pid_and_conf_file()
{
if [ -n "$OCF_RESKEY_conffile" ]; then
CONF_FILE=$OCF_RESKEY_conffile
else
CONF_FILE="/etc/haproxy/haproxy.cfg"
fi
PIDFILE="`grep -v \"#\" ${CONF_FILE} | grep \"pidfile\" | sed 's/^[ \t]*pidfile[ \t]*//'`"
if [ "${PIDFILE}" = '' ]; then
PIDFILE="/var/run/${OCF_RESOURCE_INSTANCE}.pid"
fi
}
haproxy_status()
{
if [ -n "$PIDFILE" -a -f "$PIDFILE" ]; then
# haproxy is probably running
PID=`cat $PIDFILE`
if [ -n "$PID" ]; then
if ps -p $PID | grep haproxy >/dev/null ; then
ocf_log info "haproxy daemon running"
return $OCF_SUCCESS
else
ocf_log info "haproxy daemon is not running but pid file exists"
return $OCF_NOT_RUNNING
fi
else
ocf_log err "PID file empty!"
return $OCF_ERR_GENERIC
fi
fi
# haproxy is not running
ocf_log info "haproxy daemon is not running"
return $OCF_NOT_RUNNING
}
haproxy_start()
{
# if haproxy is running return success
haproxy_status
retVal=$?
if [ $retVal -eq $OCF_SUCCESS ]; then
exit $OCF_SUCCESS
elif [ $retVal -ne $OCF_NOT_RUNNING ]; then
ocf_log err "Error. Unknown status."
exit $OCF_ERR_GENERIC
fi
if [ -n "$OCF_RESKEY_binpath" ]; then
COMMAND="$OCF_RESKEY_binpath"
else
COMMAND="/usr/sbin/haproxy"
fi
$COMMAND $OCF_RESKEY_extraconf -f $CONF_FILE -p $PIDFILE;
if [ $? -ne 0 ]; then
ocf_log err "Error. haproxy daemon returned error $?."
exit $OCF_ERR_GENERIC
fi
ocf_log info "Started haproxy daemon."
exit $OCF_SUCCESS
}
haproxy_stop()
{
if haproxy_status ; then
PID=`cat $PIDFILE`
if [ -n "$PID" ] ; then
kill $PID
if [ $? -ne 0 ]; then
kill -SIGKILL $PID
if [ $? -ne 0 ]; then
ocf_log err "Error. Could not stop haproxy daemon."
return $OCF_ERR_GENERIC
fi
fi
rm $PIDFILE 2>/dev/null
fi
fi
ocf_log info "Stopped haproxy daemon."
exit $OCF_SUCCESS
}
haproxy_monitor()
{
haproxy_status
}
haproxy_validate_all()
{
if [ -n "$OCF_RESKEY_binpath" -a ! -x "$OCF_RESKEY_binpath" ]; then
ocf_log err "Binary path $OCF_RESKEY_binpath does not exist."
exit $OCF_ERR_ARGS
fi
if [ -n "$OCF_RESKEY_conffile" -a ! -f "$OCF_RESKEY_conffile" ]; then
ocf_log err "Config file $OCF_RESKEY_conffile does not exist."
exit $OCF_ERR_ARGS
fi
if grep -v "^#" "$CONF_FILE" | grep "pidfile" > /dev/null ; then
:
else
ocf_log err "Error. \"pidfile\" entry required in the haproxy config file by haproxy OCF RA."
return $OCF_ERR_GENERIC
fi
return $OCF_SUCCESS
}
#
# Main
#
if [ $# -ne 1 ]; then
usage
exit $OCF_ERR_ARGS
fi
case $1 in
start) get_pid_and_conf_file
haproxy_start
;;
stop) get_pid_and_conf_file
haproxy_stop
;;
status) get_pid_and_conf_file
haproxy_status
;;
monitor)get_pid_and_conf_file
haproxy_monitor
;;
validate-all) get_pid_and_conf_file
haproxy_validate_all
;;
meta-data) meta_data
;;
usage) usage
exit $OCF_SUCCESS
;;
*) usage
exit $OCF_ERR_UNIMPLEMENTED
;;
esac
このファイルを保存後、haproxyのリソース定義の際に、タイプを "lsb:" ではなく "ocf:"
と指定することでこのエージェントファイルが利用されるようになります。 なお、作成したOCFファイルには実行属性を与えてください。( $ sudo
chmod 0755 haproxy )
$ sudo crm configure primitive haproxyd ocf:haproxy \
op start interval="0s" timeout="60s" on-fail="restart" \
op monitor interval="30s" timeout="60s" on-fail="restart"
\
op stop interval="0s" timeout="60s" on-fail="fence"
OCFおよびLSBのスクリプトファイルにどんなものがあるかを確認したいときは、以下のコマンドで確認できます。
$ crm ra list ocf --- OCFの確認
$ crm ra list lsb --- LSBの確認
3-4. クライアントアドレスの書換え
HAProxyを経由してアクセスされた場合、squid のログにはクライアントアドレスが HAProxyノードのアドレスしか残りません。これを回避するには、haproxy.cfgの中で "option forwardfor" ステートメントを記述した上で、squid 側でも以下の設定を行う必要があります。
■ /etc/squid/squid.conf
::
acl haproxys src 192.168.1.21/32
acl haproxys src 192.168.1.22/32
::
follow_x_forwarded_for allow haproxys
::
acl_uses_indirect_client on